Storm介绍
Storm是一个免费并开源的分布式实时计算系统。利用Storm可以很容易做到可靠地处理无限的数据流,像Hadoop批量处理大数据一样,Storm可以实时处理数据。Storm简单,可以使用任何编程语言。
在Storm之前,进行实时处理是非常痛苦的事情: 需要维护一堆消息队列和消费者,他们构成了非常复杂的图结构。消费者进程从队列里取消息,处理完成后,去更新数据库,或者给其他队列发新消息。
这样进行实时处理是非常痛苦的。我们主要的时间都花在关注往哪里发消息,从哪里接收消息,消息如何序列化,真正的业务逻辑只占了源代码的一小部分。一个应用程序的逻辑运行在很多worker上,但这些worker需要各自单独部署,还需要部署消息队列。最大问题是系统很脆弱,而且不是容错的:需要自己保证消息队列和worker进程工作正常。
Storm完整地解决了这些问题。它是为分布式场景而生的,抽象了消息传递,会自动地在集群机器上并发地处理流式计算,让你专注于实时处理的业务逻辑。
Storm的特点
storm有如下特点:
- 编程简单: 开发人员只需要关注应用逻辑,而且跟Hadoop类似,Storm提供的编程原语也很简单
- 高性能,低延迟:可以应用于广告搜索引擎这种要求对广告主的操作进行实时响应的场景。
- 分布式:可以轻松应对数据量大,单机搞不定的场景
- 可扩展:随着业务发展,数据量和计算量越来越大,系统可水平扩展
- 容错:单个节点挂了不影响应用
- 消息不丢失:保证消息处理
注意内容
Storm不是一个完整的解决方案,使用storm需要关注几点:
- 如果使用自己的消息队列,需要加入消息队列做数据的来源和产出的代码
- 需要考虑如何做故障处理
- 需要考虑如何做消息回退
Storm应用
Storm有很多应用:实时分析,在线机器学习(online machine learning),连续计算(continuous computation),分布式远程过程调用(RPC)、ETL等。Storm处理速度很快:每个节点每秒钟可以处理超过百万的数据组。它是可扩展(scalable),容错(fault-tolerant),保证你的数据会被处理,并且很容易搭建和操作。
Storm模型
Storm实现了一个数据流(data flow)的模型,在这个模型中数据持续不断的流经一个由很多转换实体构成的网络.一个数据流的抽象叫做流(stream),流是无限的元组(Tuple)序列.元组是一个可以表示标准数据类型和用户自定义类型的数据结构,每一个流由唯一的ID来标识.这个ID可以用来构建拓扑中各个组件的数据源.
并发模型(worker/executor/task)
在一个Storm集群中.Storm主要通过以下三个部件来运行拓扑
- 工作进程(worker processes)
- 执行器(executors)
- 任务(task)
work,exexutors,task的相关关系
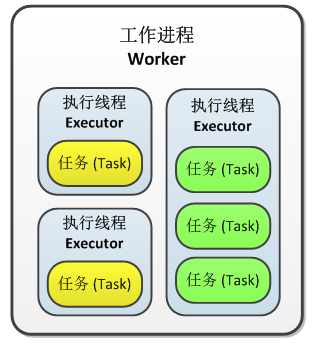
在Worker中运行的是拓扑的一个子集.一个worker进程是从属于某一个特定的拓扑,在一个worker进程中会运行一个或多个与拓扑中组件相关的exector.一个运行中的拓扑就是由这些运行与storm集群的很多机器上的进程组成的.
一个executor是由worker进成上的一个线程,在executor中可能会有一个或者多个task,这些task都是为同一个组件(spout或者blot)服务的.
task是实际执行数据处理的最小工作单元(task不是线程).代码中实现的每一个spout或者blot都会在集群中运行很多task.在拓扑的整个生命周期中,每个task的数量保持不变,不过每个组件的executor数量有可能会随着时间变化.在默认情况下task数量和executor的数量是一样的.默认情况下Storm会在一个线程上运行一个task
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout);
在上面的代码中,我们为GreenBolt配置了2个初始线程(executor)和4个关联任务(task).这样,每一个执行线程中会运行2个任务.如果在设置blot的时候不指定task数量,那么每个executor和task的数量默认设置为1.